

딥러닝의 발전과 함께, 몇 단어로 구성된 문장만으로 그림을 생성하는 인공지능이 유행하고 있습니다. 단순한 그림 한 장 만드는 것부터 영상을 생성하기 까지 지속적으로 발전하고 있는데요. 인물의 사진으로 입술의 움직임을 만들어낼 수 있는 기술인 ‘립 제너레이션(lip generation)’ 함께 살펴볼까요?
립 제너레이션 기술
립 제너레이션 기술은 오디오와 영상 속 인물의 입술 발화를 맞추는 AI 기반의 립싱크 기술입니다. 인물의 영상 또는 이미지와 오디오를 입력하면 오디오 싱크에 맞춰 말하는 듯한 입술의 영상을 생성하죠. 최근에는 영상과 같은 디지털 커뮤니케이션이 활발해지고 있어, 실제 입술 움직임을 동기화하는 것이 더욱 중요해지고 있기 때문에 립 제너레이션 기술에 대한 연구도 활발히 진행되고 있습니다.

립 제너레이션의 결과 생성되는 립싱크 ⓒhttps://medium.com/
립 제너레이션과 함께 발전하는
음성변환 기술
립 제너레이션과 함께 발전하는 기술들이 있습니다. 대표적으로 음성변환(speech to speech translation, S2ST) 기술인데요. 음성변환은 특정 언어의 음성을 타겟 언어의 음성으로 변환하는 기술입니다. 음성인식(automatic speech recognition, ASR), 번역(machine translation, MT), 음성생성(text to speech, TTS)의 순서로 입술의 움직임을 동기화하는 방식으로 활용되고 있습니다. 이러한 과정에서 신호처리를 통해 음성의 특징을 추출하고, 딥러닝을 통해 번역을 수행한 후, 해당 번역 결과를 음성으로 합성하는 과정이 포함됩니다.

음성변환 기술을 나타낸 그림 ⓒhttps://www.techexplorist.com
LipGAN과 Wav2Lip
영상이나 음성합성 기술에 대한 여러 연구가 진행되고 있는만큼, 립 제너레이션에 대한 연구도 꾸준히 발전하고 있습니다. 가장 대표적인 입술 움직임 동기화 기술은 2019년 발표된 LipGAN(논문제목 Towards Automatic Face-to-Face Translation)입니다. 영상과 번역된 오디오를 합성하여 실제 번역된 오디오를 말하는 것과 같은 영상으로 입술 움직임을 생성하는 기술입니다.
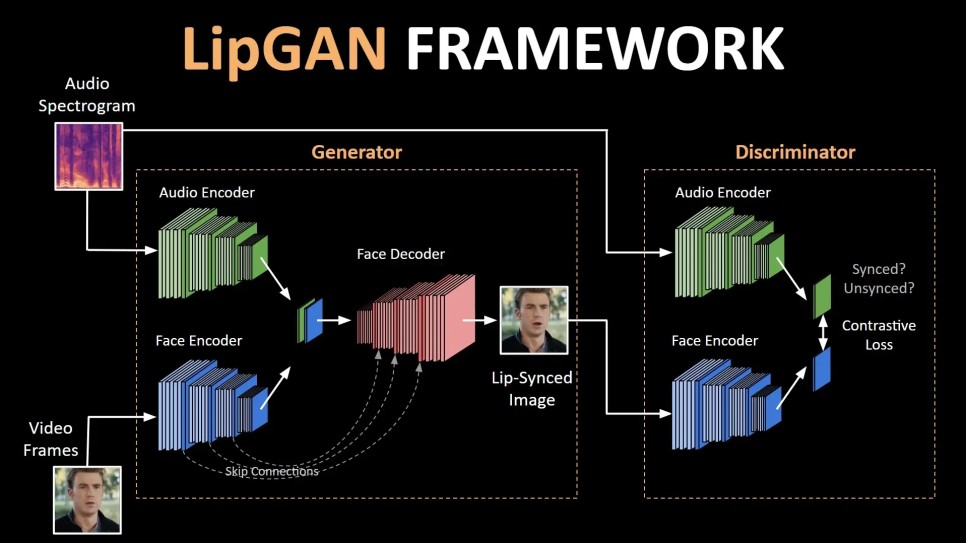
LipGAN의 네트워크 구조 ⓒhttps://medium.com/
앞서 설명한 음성변환 기술에 음성인식, 번역, 음성생성, CycleGAN을 활용하여 만들어낸 목소리를 타겟 목소리와 비슷하게 조정하고, 자연스러움을 연출하는 음성전달(voice transfer) 과정에 LipGAN을 사용하면 특정 언어로 발화된 영상을 다른 언어로 립싱크한 영상으로 변환됩니다.
2020년 제안된 기술인 Wav2Lip은 이전 LipGAN에서 더 발전된 모델입니다. 이 기술은 음성의 길이, 어휘 개수 등에 제한되지 않고 더 정확한 립싱크를 맞추는 모델을 제안하면서 립 제너레이션의 우수함을 판단할 수 있는 새로운 평가 지표로 제안하였습니다.
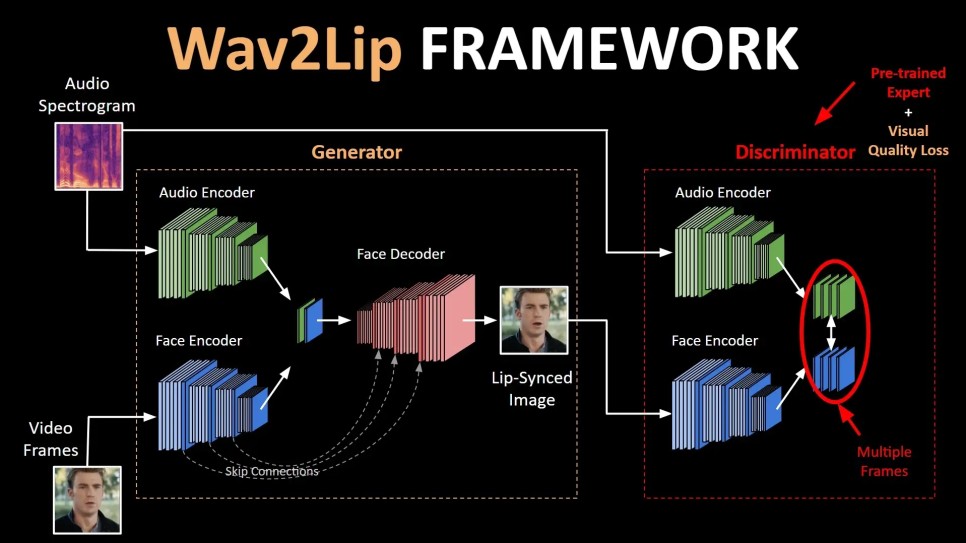
Wav2Lip의 네트워크 구조 ⓒhttps://medium.com/
LipGAN에 비해 Wav2Lip은 더 우수하고 강력한 립싱크 판별기인데요, 판별자(Discriminator)가 여러 프레임으로 확장되어 생성된 입술 움직임이 얼마나 정확한 지 결정할 때에 시간적인 문맥을 이해하는 부분을 추가하였습니다.
또한 사전훈련(pre-train)하여, 모델을 훈련하는 동안 가중치가 고정되어 생성기(generator)의 시각적 아티팩트에 영향을 받지 않고 생성된 입술 움직임의 정확성에만 집중할 수 있습니다. 출력 프레임의 전체 얼굴이 실제처럼 보이도록 시각적 품질과 관련된 함수를 추가하여 이전 모델인 LipGAN에서 발견된 아티팩트를 최소화하였습니다.
더욱 흥미로운 것은, Wav2Lip의 저자들이 공개한 프로젝트 페이지의 실제로 훈련된 네트워크를 통해 영상 파일(video)과 음성 파일(audio)을 입력하면 해당 네트워크의 결과물로 립 제너레이션 된 영상을 획득할 수 있습니다. 아래 홈페이지에서 음성과 목소리의 짝을 맞추어 립 제너레이션 해보세요.
Interactive Demo Select a video file (Max 20 seconds): Select an audio file (or) video with audio (Max 20 sec): Or choose from the example pairs below! Using our open-source code , you can attempt to lip-sync higher resolution/longer videos. You will be able to tune the inference parameters and henc…
bhaasha.iiit.ac.in
이후에도 Wav2Lip에 이어 Attention-Based Lip Audio-Visual Synthesis for Talking Face Generation in the Wild와 같은 개선된 여러 기술들이 공개되고 있습니다.
해당 기술이 사용될 수 있는 분야
애니메이션을 만들 때 프리스코어링(prescoring) 방법을 사용하는데요, 이러한 프리스코어링은 소리부터 먼저 녹음한 후 소리에 맞춰 작화(그림을 그리는)를 하는 방식을 사용합니다. 이러한 프리스코어링은 생동감있는 화면을 만들어내기 좋지만 시간과 돈이 많이 드는데요, 립 제너레이션 기술이 이를 보조할 수 있습니다.

한국의 AI인간 ⓒhttp://www.koreatimes.co.kr/
또한 AI인간(virtual human)의 경우에도, 얼굴 생성(face generation) 기술이 사용됩니다. 이러한 얼굴 생성에는 발화 시의 입술 모양도 필수적으로 고려되어야 하는데요, 이 때 참조가 되는 현실 인간의 영상 없이도 립 제너레이션 기술을 활용하여 AI인간의 얼굴과 음성만으로 충분히 구현해낼 수 있을 것입니다.
앞으로도 영상합성 기술에 꾸준히 사용될 립 제너레이션 기술, 더욱 더 발전하여 더더욱 자연스러운 입술 움직임을 만들어낼텐데요. 인공지능 기반 얼굴 합성 변조 기술인 딥페이크 시장이 커지면서 더욱 빛을 발할 것 같습니다. 앞으로도 립 제너레이션 기술의 발전을 기대해주세요.



